推薦系統就像是一種 “訊息過濾系統”,會依照特定的規則進行過濾,並預測用戶對商品的評分或偏好,
透過推薦系統能夠降低消費者的選擇時間,提高衝動購買的機率,幫助用戶找到最適合自己、最感興趣的商品。
推薦系統的演算法發展至今,Python、R 等許多程式都有提供相關套件進行推薦系統的演算法運算,
因此就目前而言,不是著重於如何實現這些演算法運算,而是透過哪個演算法才能夠解決當下的問題。
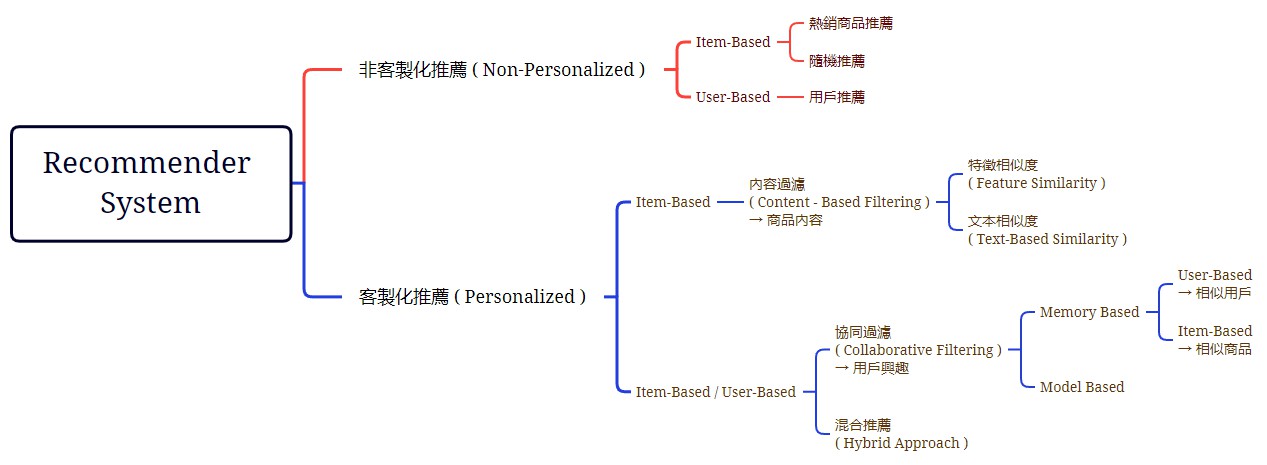
非客製化推薦 ( Non-Personalized )
在企業、商業模式草創初期,銷售的商品品項不多,又或只專注於銷售單一商品造成銷售量差異懸殊時,
無須使用客製化推薦,以非客製化推薦效益較高。
Item-Based
熱銷商品推薦
透過所有用戶對於商品的熱度或點閱率等方式來進行商品推薦 ( 對於時效性議題、商品非常有效 )
1 | import pandas as pd |
隨機推薦
隨機投遞商品或物品給用戶 ( 隨機的結果可能比運算的結果還要好 )
User-Based
用戶推薦/建議
計算觀看相似商品的用戶,可能會對哪些商品有興趣;可將此應用至草創初期,
即當用戶隨意點一項商品後,直接推薦相似的商品給其他用戶。
- 透過窮盡法將所有可能列舉出來(排列組合),不考慮不同評分間的差異,取出推薦組合次數最多的商品。
1 | from itertools import permutations # 使用 Permutation tool 進行取後不放回的抽樣(列出所有可能的排列組合) |
客製化推薦 ( Personalized )
Item-Based
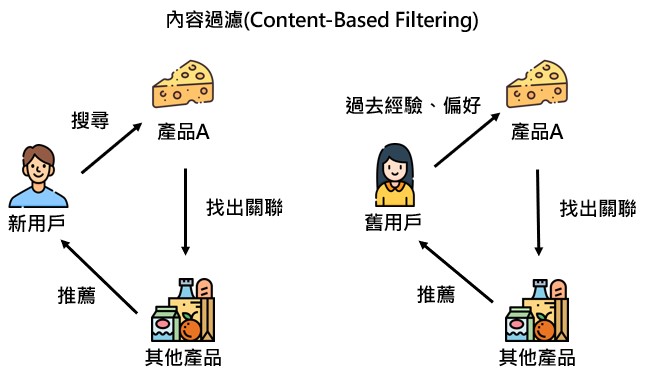
內容過濾 ( Content-Based Filtering )
針對商品內容進行分析,找出商品間的關聯性並進行分類 ( 利用商品屬性 Matrix,進行相似度分析 ),
可解決冷啟動問題 ( 解釋性、效果較佳 ),並且可針對用戶過去喜歡的商品,推薦類似品項給用戶。
特徵相似度 ( Feature Similarity )
適合用於推薦新用戶,當新用戶進入頁面時,可藉由一些判斷標準 ( 點選的商品、購買目的、用途等 ),
了解新用戶的興趣並進行推薦,不需等新用戶導覽完全部商品後再進行推薦。
- Jaccard Similarity ( Jaccard 相似度 )
所有聯集中,有多少比例是交集,判斷哪些商品出現的機率較高,但無不同商品間評分的差異。
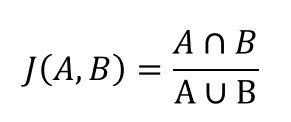
1 | from sklearn.metrics import jaccard_score # 使用 sklearn 的 matrics 來計算 jaccard 相似度 |
文本相似度 ( Text-Based Similarity )
以商品 text 為主,利用協同過濾 ( Item-based ) 對無特定 Feature 進行計算
- 很多商品無法被分類或參照,僅有一些文字可作為參考,因此可藉由 NLP ( Nature Language Processing ) 領域的 TF-IDF ( Terms Frequency — Inverse Document Frequency ) 演算法,求出每篇文章或每個商品文案中,每個字詞的重要程度。

1 | from sklearn.feature_extraction.text import TfidfVectorizer # TF-IDF 套件 |
- Cosine Similarity 餘弦相似度
兩個向量之間的餘弦值,能夠透過歐基理得點積公式求出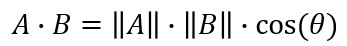 將兩邊同除兩向量的純量乘積後得出(類似標準化過程)
將兩邊同除兩向量的純量乘積後得出(類似標準化過程)
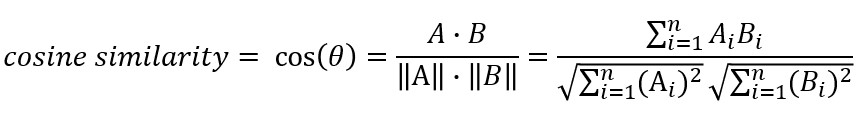 Cosine Similarity
Cosine Similarity
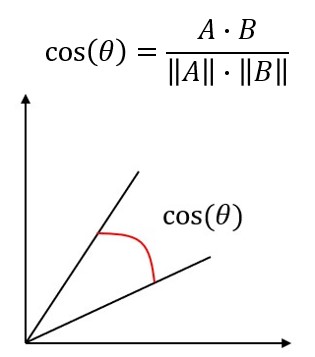
餘弦值會介於 -1 ~ 1 之間,若兩個向量方向接近則會越接近 1 ,反方向則為 -1,而 0 代表兩者間是獨立的
1 | cosine_similarity_array = cosine_similarity(tfidf_df) |
Item / User-Based
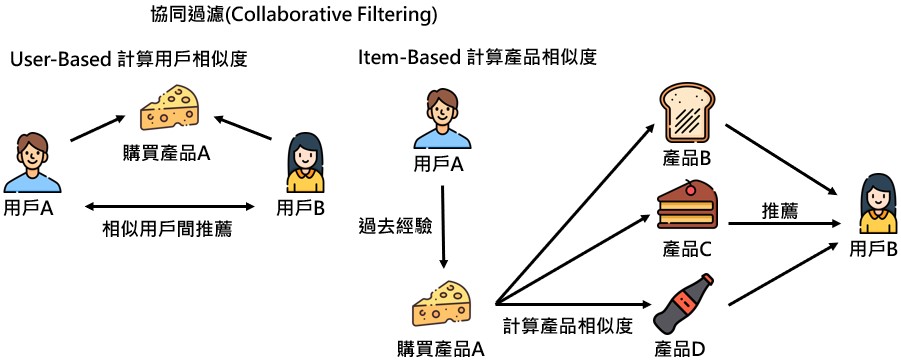
協同過濾 ( Collaborative Filtering )
演算法的計算資料,是來自於用戶對於特定商品的評分或購買項目
Memory-Based
Item-Based
「買了什麼東西,還會買什麼東西」,這樣的情境其中一種解決方案就是使用協同過濾,透過用戶瀏覽過的商品決定如何進行推薦,如:喜歡A商品也喜歡B/C/D商品的用戶有多少,透過計算商品間的相似程度,並將相似的商品推薦給用戶。- 發掘用戶潛在興趣
- 推薦結果容易變化,缺乏穩定性
- 冷啟動問題 ( Cold Start ),初期推薦效果非常差
- 資料稀疏問題,需要以 KNN/MF 矩陣分解來解決
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# 透過前面的 TF-IDF Matrix (tfidf_df) 來選出用戶有選過的 item 並以加權平均把用戶的 Feature 計算出來,再計算 Cosine Similarity
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
user_item = {
'user':['userA','userA','userA','userB','userB','userA'],
'item':['itemA','itemB','itemC','itemA','itemB','itemA']
}
user_item = pd.DataFrame(user_item)
# 篩選出用戶曾經買過的商品,每個商品總共被用戶買過幾次
list_of_items = pd.DataFrame(user_item.groupby(['user','item'])['item'].count())
list_of_items.columns = ['counts']
# 取一位用戶
userA = list_of_items.loc['userA'].reset_index()
# 以 userA 計算加權 TF-IDF score
tfidf_user_enjoyed = tfidf_df.reindex(userA.item.tolist())
# 計算 user 的 TF-IDF score
tfidf_user_prob = tfidf_user_enjoyed.mean()
# 將用戶已瀏覽過的商品剔除 TF-IDF 矩陣外,以剩下的商品來計算餘弦相似度
non_user_items = tfidf_df.drop(list_of_items.loc['userA'].index,axis=0)
# sklearn 預設只能讀取二維 array,使用 reshape 來轉換成僅有一列,而 -1 則是讓 numpy 自行計算總共要幾列(讓矩陣自動變成二維 array)
cosine_similarity_userA = cosine_similarity(tfidf_user_prob.values.reshape(1,-1),non_user_items)
user_prof_similarities_df = pd.DataFrame(cosine_similarity_userA.T,index=non_user_items.index,columns=['similarity_score'])
sorted_similarity_df = user_prof_similarities_df.sort_values(by='similarity_score',ascending=False)
sorted_similarity_dfUser-Based
「用於不同的商品間,用戶與用戶之間的相似度」,針對用戶興趣進行分析,找出相同類型的群體行為來進行決策,計算用戶間的相似程度 (ex: Cosine-Similarity ),並將用戶有興趣的商品(TopN)推薦給相似用戶;同時,需先蒐集用戶資訊,如:評價、購買記錄等- 對於所有的商品評分都減掉各自的平均,就會變成皮爾森相關係數 ( Pearson Correlation Coefficient ),比 Cosine Similarity 多減掉平均
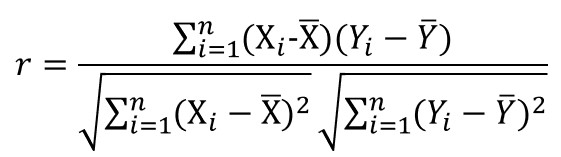
- 隨著資料累積時間增加,推薦系統會越來越穩定,且能在商品上架前計算演算法矩陣
- 無法推薦用戶潛在感興趣的商品、特徵難以抽取,有冷啟動問題(Cold Start),沒有用戶資料便無法推薦
- 資料稀疏問題,需要以 KNN/MF 矩陣分解來解決
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
import pandas as pd
user_item_rating = {
'user':['userA','userB','userC','userD','userA','userB','userC','userD'],
'item':['itemA','itemB','itemC','itemD','itemB','itemA','itemA','itemC'],
'rating':[5,3,2,1,2,5,4,3]
}
user_item_rating = pd.DataFrame(user_item_rating)
user_ratings_pivot = user_item_rating.pivot(index='user',columns='item',values='rating')
# 計算平均以中心化各項商品的評分,並將各用戶的數據減掉各自商品的平均
avg_ratings = user_ratings_pivot.mean(axis=1)
user_ratings_pivot = user_ratings_pivot.sub(avg_ratings,axis=0)
# 將沒有值的地方先簡單補上 0
user_ratings_pivot_filled = user_ratings_pivot.fillna(0)
# 將矩陣轉置為計算 User 間的相似度,並傳入 DataFrame
similarities = cosine_similarity(user_ratings_pivot_filled.T)
user_ratings_cos = pd.DataFrame(similarities,index=user_ratings_pivot_filled.index,columns=user_ratings_pivot_filled.index)
# user_ratings_cos.apply(lambda x: round(x, 2))
# 獲得與 user_A 相似的用戶
ordered_similarities_userA = user_ratings_cos.loc['userA'].sort_values(ascending=False)
ordered_similarities_userA計算出 User-based 的 Cosine Similarity 矩陣後,會有許多地方出現遺漏值 ( Missing Value ),原因在於不是每個用戶都會對各個商品評分或按讚,因此需透過補值的方式來填補遺漏值,如: KNN 插值等。
- KNN (K-Nearest Neighbors)
以周圍指定的 K 個數中,佔比最多的那個類別就歸類為該類別,避免指定偶數項;當數字完全相同時,KNN 可能就會選不出來(如果以 Cosine 則可能比較難重複),或是會隨機從中挑一個出來。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32from sklearn.neighbors import KNeighborsRegressor
import pandas as pd
import numpy as np
user_item_rating = {
'user':['userA','userB','userC','userD','userE'],
'itemA':[5,np.nan,3,5,2],
'itemB':[5,3,2,1,4],
'itemC':[4,3,1,1,5]
}
user_item_rating = pd.DataFrame(user_item_rating).set_index('user')
user_item_rating_df = user_item_rating.copy()
# 將商品評分資料中,想要預測的商品資料欄位刪除
user_item_rating.drop('itemA',axis=1,inplace=True)
# 將我們想要預測的用戶資料翠取出來,之後 KNN 就會根據現有的這些欄位,來預測用戶其他沒有評分的分數
target_user_x = user_item_rating.loc[['userA']]
# 將尚未填補、含有 NaN 缺值的資料放到要用於訓練的 y
other_users_y = user_item_rating_df['itemA']
# 藉由前面有 NaN 的列,篩選出沒有 Nan 的資料行
other_users_x = user_item_rating[other_users_y.notnull()]
# 將有 Nan 的去掉
other_users_y.dropna(inplace=True)
# 初始化 KNN 模型,並以 cosine 相似度來計算(記得這裡的資料都還沒有計算與弦相似度)
user_knn = KNeighborsRegressor(metric='cosine',n_neighbors=4)
# 訓練與預測 KNN 模型
user_knn.fit(other_users_x,other_users_y)
user_user_pred = user_knn.predict(target_user_x)
# 明確有預測結果的欄位,來預測特定 User 對特定欄位的評分值(這裡是 item_A)
# KNN Regression 則是將周圍的 10 個資料點用於計算平均後輸出
# 這個插值法一樣也能倒過來使用,亦即用原先用 User 的評價來補齊其他評價;這次則可以用其他商品來當作訓練集,來預測特定商品的分數
user_user_pred- Matrix Factorization
透過 KNN 填補用戶沒有填寫的評分,僅能用在商品品項不多的情況下;若商品品項較多、使用過該商品的比例非常低, KNN 所預測出來的值將會不準確,因此需使用矩陣分解(Matrix Factorization)來解決資料稀疏的問題,即透過 MF 可以將原本的矩陣拆解為兩個矩陣相乘 ( 用更少的資料來代表原本的矩陣 ),並抽取出特徵矩陣 ( User 特徵 + Item 特徵 ),其中 User 特徵又稱為潛藏特徵(Latent Factors)。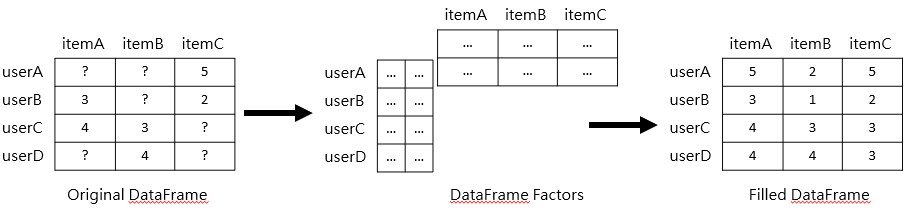 MF 分解雖然會造成資訊損失(Information Loss),但可以解決運算量、資料稀疏造成協同過濾演算法難以計算的困境,而如何使用 MF 拆開兩個矩陣,最常被應用的方法是奇異值分解(Singular Value Decomposition)。
MF 分解雖然會造成資訊損失(Information Loss),但可以解決運算量、資料稀疏造成協同過濾演算法難以計算的困境,而如何使用 MF 拆開兩個矩陣,最常被應用的方法是奇異值分解(Singular Value Decomposition)。
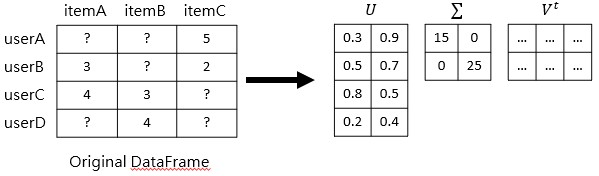 SVD 為一種降維工具,可拆解成 U, Sigma, Vt 三個矩陣,而對角矩陣可以針對 U 和 Vt 進行線性變換,而 Sigma 則作為這兩個矩陣的中介,並且 Sigma 被稱為奇異值。
SVD 為一種降維工具,可拆解成 U, Sigma, Vt 三個矩陣,而對角矩陣可以針對 U 和 Vt 進行線性變換,而 Sigma 則作為這兩個矩陣的中介,並且 Sigma 被稱為奇異值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26from scipy.linalg import svd
import pandas as pd
import numpy as np
user_item_rating = {
'user':['userA','userB','userC','userD','userA','userB','userC','userD'],
'item':['itemA','itemB','itemC','itemD','itemB','itemA','itemA','itemC'],
'rating':[5,3,2,1,2,5,4,3]
}
user_item_rating = pd.DataFrame(user_item_rating)
user_ratings_pivot = user_item_rating.pivot(index='user',columns='item',values='rating')
# 計算平均以中心化各項商品的評分,並將各用戶的數據減掉各自商品的平均
avg_ratings = user_ratings_pivot.mean(axis=1)
user_ratings_pivot = user_ratings_pivot.sub(avg_ratings,axis=0)
# 將沒有值的地方先簡單補上 0
user_ratings_pivot_filled = user_ratings_pivot.fillna(0).to_numpy()
# 計算 SVD 的三個矩陣
U, sigma, Vt = svd(user_ratings_pivot_filled)
# 恢復原先的矩陣,將計算出的矩陣去中心化
U_sigma_Vt = np.dot(np.dot(U,sigma),Vt)
uncentered_ratings = U_sigma_Vt + avg_ratings.values.reshape(-1,1)
calc_pred_ratings_df = pd.DataFrame(uncentered_ratings,index=user_ratings_pivot.index,columns=user_ratings_pivot.columns)
# 以 SVD 進行預測推薦
userA_ratings = calc_pred_ratings_df.loc['userA',:].sort_values(ascending=False)
userA_ratings1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# 檢驗 SVD 的表現程度
from sklearn.metrics import mean_squared_error
# 1. 透過遮罩來藏起左上角的 3*3 的值
actual_values = user_ratings_pivot.fillna(0).iloc[:3,:3].values
# 2. 以平均來預測左上角的 3*3 的值
col_mean = np.nanmean(user_ratings_pivot.to_numpy(),axis=0)
inds = np.where(np.isnan(user_ratings_pivot.to_numpy()))
user_ratings_pivot.to_numpy()[inds] = np.take(col_mean,inds[1])
avg_values = user_ratings_pivot.iloc[:3,:3].values
# 3. 將上面 SVD 計算出來的矩陣取出遮罩 3*3 的範圍
predicted_values = calc_pred_ratings_df.iloc[:3,:3].values
# 透過遮罩產生 Non-Nan 的真值矩陣
mask = ~np.isnan(actual_values)
# 比較單純透過平均和使用 SVD 的預測結果
print(mean_squared_error(actual_values[mask],avg_values[mask],squared=False))
print(mean_squared_error(actual_values[mask],predicted_values[mask],squared=False))- 對於所有的商品評分都減掉各自的平均,就會變成皮爾森相關係數 ( Pearson Correlation Coefficient ),比 Cosine Similarity 多減掉平均
Model-Based
透過用戶歷史紀錄訓練出模型進行預測,如:LSTM 預測時間序列,當今天看完第一集會想接續看第二、第三集等。
如何選擇協同過濾要使用 User-Based 還是 Item-Based 呢?
User-Based:通常推薦最熱門(點擊率最高)的商品,但該商品不一定是用戶最有興趣的。
Item-Based:容易推薦長尾 (long-tail) 的商品(購買聲量不高,但會持續購買的商品)。
- Case1:電商擁有許多用戶資料(既有客戶、潛在客戶、沉睡客戶等),若使用 User-Based 計算用戶相似度,將會耗費大量的時間,因此會使用 Item-Based 的協同過濾系統。
- Case2:部落格是以提供內容為主的網站,在推薦文章給讀者時,由於文章會一直更新,較適合使用 User-Based 的協同過濾系統。
混合推薦(Hybrid Approach)
- 不同商品適合不同的推薦方式,因此業界許多推薦系統都會混合不同的方法,如:結合內容過濾與協同過濾、結合機器學習演算法來建立推薦系統,以增進推薦的效率。
推薦系統的限制與缺點
冷啟動(Cold Start)
碰到新用戶、新商品的情況下,沒有(被)使用或(被)瀏覽的商品,在某些推薦系統上將會發生無法推薦的窘境,我們該怎麼推薦商品?
解法:先以其他 Item-Based 的方式,透過新商品的屬性、新用戶的特徵來推薦給用戶,累積一定的使用資料後,再慢慢放入協同過濾所推薦的內容。
- 冷門商品在協同過濾系統下,都不會成為推薦商品
- 資料量不足以致於推薦系統效果不佳、無法使用
探索問題(Exploit & Explore, EE)
Exploit 是指使用已知用戶偏好來做分析; Explore 是指探索用戶未知的興趣或者偏好。
解法:部分使用模型預測、熱門、隨機等方法;而如何挑選,將透過商業角度或者AB test的方式進行。
資料稀疏(Data Sparsity)
某電商平台銷售同類型、過多相似的商品(資訊量過多)時,可能造成資料稀疏(Data Sparsity)的問題,即當用戶無法瀏覽大部分商品時,將會造成蒐集資料上的稀疏。
結語
本篇文章大致講解推薦系統的基本概念,並附上 Python Code 的範例供參考 ( 數據為隨機值,運算結果可能會怪怪的 );推薦系統的概念大致相同,應著重於如何將該系統、演算法應用於不同情境下,並解決當下的問題。
- 一般應用:推薦系統是根據用戶相似度、商品相似度排序來進行推薦。
- 實務應用:需依照想達成的目的、解決的問題來進行調整,如:透過推薦系統加深用戶付費深度等,不一定會只考慮相似度進行;同時,後續若要進行部署也是一大挑戰,需要考量到推薦系統的運算時間、資料的標準化、是否需要即時推薦等問題,以及系統的穩定性和成效追蹤,需要有完整的數據監控系統和 AB test 方法來進行。
作者:Ian Chang
網址: https://yuyaochang.github.io/2022/11/03/Recommendation_System_推薦系統概念介紹_Python/
版權聲明:Blog中所有文章除特別聲明外,均採用 CC BY-NC-SA 3.0 TW 許可協議,若要轉載請註明出處